
Photo by Luke Chesser on Unsplash
Something broke in your rank reports in September 2025, and you probably didn't get a memo. Google quietly killed the &num=100 parameter that rank trackers used to read the top 100 results in one request. Overnight, third-party tools needed up to 10x more requests to see the same data. Costs jumped from roughly $1.05 to $8–$12 per 1,000 keywords tracked. Some tools just stopped showing anything past the top 20.
At the same time, AI Overviews started eating clicks. Ahrefs measured a 58% drop in click-through rate for the top organic result on queries that show an AI Overview.
So here's the question website rank tracking has to answer in 2026: are your pages still getting found, and where? Not for one keyword you picked in a tool. For every page you actually own.
This guide shows you how to set up website rank tracking without code, scrapers, or a $99-a-month contract. You point a tool at your sitemap, connect Google Search Console and Bing, and watch position, clicks, and indexing for every URL on your site. No migration. No tags to install. Here's the whole playbook, current as of June 2026.
What is website rank tracking?
Website rank tracking is defined as monitoring where each page on your site appears in search results over time. Modern rank tracking watches four signals per URL: search position, clicks and impressions, indexing status, and on-page SEO health. It tells you whether the pages you own are getting found, and whether that's trending up or down.
The old way meant picking a list of keywords and asking a tool to scrape Google for your position on each one. That still works, but it's the wrong unit. You don't ship keywords. You ship pages. A single page ranks for dozens of queries you'd never think to add to a tracker, and it's the page you can actually fix.
Page-first tracking flips the model. You start from the URLs in your sitemap and ask: where does each one rank, how much traffic does it pull, is it indexed, and is its SEO healthy? That's the view this guide builds.
Why rank tracking quietly broke in 2025
Two changes in 2025 made old-school rank tracking less reliable and more expensive. If your reports look weird, this is why.
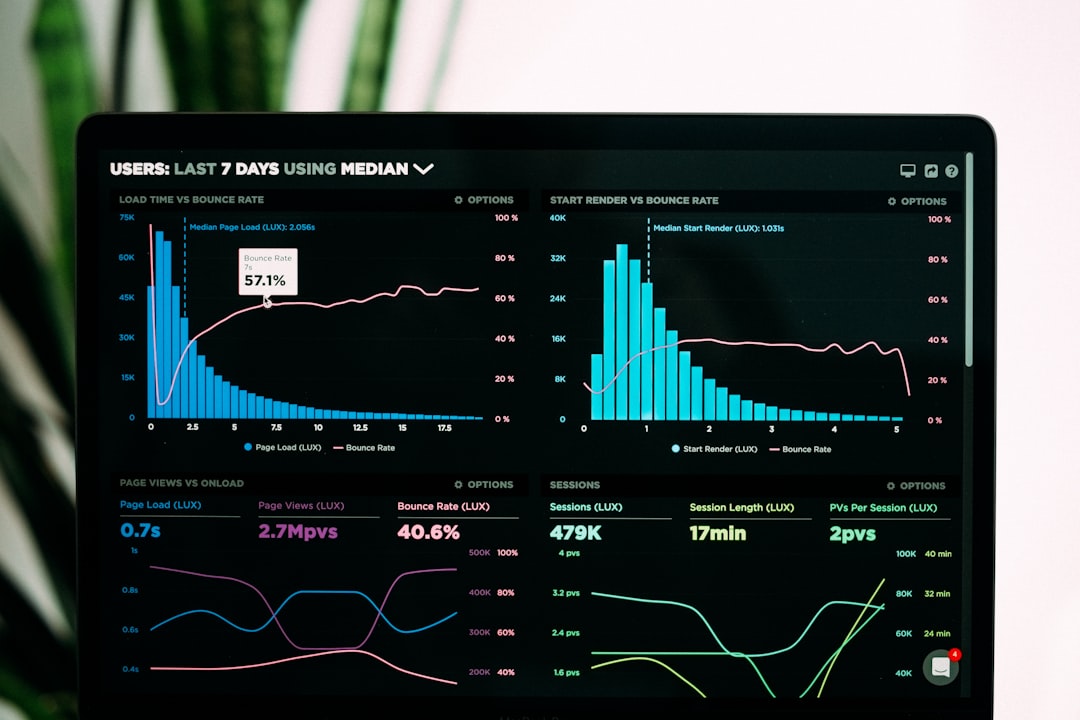
First, the num=100 change. On September 11, 2025, Google removed the URL parameter that let tools pull 100 results in a single request. Rank trackers now have to paginate, so every keyword costs up to 10x more requests. Per-keyword costs across the industry rose from about $1.05 to between $8 and $12 per 1,000 keywords, according to reporting compiled by Lead Advisors. AccuRanker and others capped daily tracking to the top 20–30 results to stay stable.
Second, that same change scrubbed bot-driven impressions out of Google Search Console. Many sites saw impressions fall and average position "improve" overnight, as Search Engine Land explained. It wasn't a real ranking gain. The low-position impressions just stopped being counted.
Metric | Before Sept 2025 | After Sept 2025 | Why |
|---|---|---|---|
Tracker cost / 1k keywords | ~$1.05 | $8–$12 | Pagination replaces |
Visible SERP depth | Top 100 | Often top 20–30 | Tools cap to control cost |
GSC impressions | Inflated by bots | Lower, cleaner | Bot impressions removed |
GSC average position | Worse-looking | Better-looking | Fewer low spots counted |
The takeaway: SERP-scraping got pricier and shallower at the exact moment search got harder to read. First-party data from Google and Bing didn't.
The contrarian fix: track pages, not just keywords
Here's the conventional wisdom that's now wrong: "buy a big rank tracker, load 500 keywords, and watch positions every morning." In 2026 that's an expensive way to watch noise.
Keyword positions swing hour to hour based on location, personalization, and device. John Mueller of Google has repeatedly pointed out that Search Console positions are real but vary by location and personalization, so they shouldn't be your only metric. Chasing a single number daily tells you almost nothing.
The fix is to change the unit. Track the page, not the keyword. Pages are stable, they map to something you can edit, and one page captures every long-tail query it ranks for, including the ones you never added to a tool.
This also matches where search is heading. As Kevin Indig puts it, SEO is moving "from a click game to an influence game," and AI traffic "is not the leading metric in this era." When clicks get harder to win, you want a durable view of which pages are visible, indexed, and healthy, not a twitchy keyword leaderboard.
That's the case for first-party, page-level tracking. It survived 2025 because it never depended on scraping the SERP.
The Page Pulse framework: 4 signals per page
Track one thing per page and you'll misread it. Track four and you get a pulse. The Page Pulse framework is a simple model: for every URL you own, watch four signals together. Each one catches a failure the others miss.
Position tells you visibility. Where does the page rank for its main queries?
Traffic tells you demand. How many clicks and impressions is it pulling?
Index status tells you eligibility. Is the page even in Google and Bing's index?
SEO score tells you fixability. Is the on-page health holding the page back?
Read them as a set. A page can rank #3 and still get few clicks if its title is weak. A page can have a perfect SEO score and pull zero traffic because it was never indexed. The combination points straight at the cause.
Signal | What it tells you | Source | Healthy sign |
|---|---|---|---|
Position | Visibility for a query | GSC / Bing | Top 10 and stable or rising |
Traffic | Real demand reaching you | GSC / Bing clicks | Clicks tracking impressions |
Index status | Eligible to rank at all | Indexing API / IndexNow | "Indexed", not "Pending" |
SEO score | On-page fixability | On-page audit | 85+ with no critical issues |
Run a Page Pulse check weekly. You're not hunting for a single number. You're scanning for a page where one signal is out of line with the rest. That mismatch is your next task.
How to set up rank tracking without code
You don't need to install a script, add a tag, or move your site. Sitemap-based rank tracking reads public data Google and Bing already collect about you. Here's the setup, start to finish.
Step 1: Make sure your sitemap is live and has lastmod
Your sitemap is the source of truth for which URLs get tracked. Most platforms generate one at /sitemap.xml. Confirm it loads and that entries include a <lastmod> date. That date is what tells a tracker a page changed and needs a fresh look.
Step 2: Connect Google Search Console
GSC is your free, first-party rank data for Google. It reports real position, clicks, and impressions per page, straight from Google. No scraping, no num=100 problem. Connecting a verified GSC property also proves you own the domain, which unlocks indexing submission.
Step 3: Connect Bing Webmaster Tools
Bing is not optional in 2026. It holds about 9.8% of US search and roughly 17.6% of US desktop search, per Backlinko, and it's the index behind ChatGPT search. Connecting Bing gives you a second set of first-party position and click data, plus indexing reach into AI answers.
Step 4: Import your URLs and let the baseline build
Point the tracker at your sitemap. It pulls in every URL, matches each one to GSC and Bing data, and records a baseline for position, clicks, indexing, and SEO score. From there it refreshes daily. With Quillly, this is the "rank and track the pages you already have" flow: connect once, and every URL in your sitemap is tracked with no code added to your site.
That's it. No tags, no migration, no per-keyword bill. The data was always yours. You're just finally reading it page by page.
Track, diff, notify: how sitemap tracking actually works
Under the hood, sitemap-based tracking runs a simple loop. Builders will recognize it. The Track-Diff-Notify loop has three steps that repeat on a schedule.
Track. Fetch the sitemap and read every URL plus its
lastmoddate. This is the full list of pages you care about.Diff. Compare each URL's
lastmodagainst the last value seen. New URL, or a date that moved forward? That page changed and needs attention.Notify. For changed pages, ping the search engines so they re-crawl. That means IndexNow for the Bing network and the Google Indexing API when Search Console is connected.
The clever part is what it avoids. There's no crawler hitting your server, no JavaScript on your pages, and no separate database of "tracked keywords" to maintain. A changed lastmod is the only trigger. That's why it works on a static site, a Next.js app, or a no-code builder equally well.
The same loop also keeps your index status honest. When a page changes, its status resets so the next pass re-checks whether Google and Bing actually picked up the new version, instead of trusting a stale "indexed" flag from weeks ago. If indexing is a recurring headache, our guide on getting your blog indexed pairs well with this.
This is why the approach scales. Whether you have 12 pages or 1,200, the cost is one sitemap fetch and a diff, not 1,200 SERP scrapes.
Rank tracking approaches compared
There are three ways to track rankings in 2026. They aren't equal anymore. Here's how they stack up after the 2025 changes.
SERP scrapers (Ahrefs, Semrush) | GSC / Bing alone | Sitemap + first-party tracking | |
|---|---|---|---|
Data source | Scraped SERPs | Your own search data | Your own search data |
Unit tracked | Keywords you pick | Pages and queries | Every URL in your sitemap |
| Higher cost, less depth | None | None |
Bing / AI coverage | Add-on or none | Native | Native |
Setup | Account + keyword list | Property verification | Connect once, no code |
Typical cost | ~$55+/mo for 250 keywords | Free, but raw | Flat, page-based |
SERP scrapers still have a place. If you need competitor positions or SERP-feature tracking across markets, they're built for it, and Semrush position tracking starts around $55/month for 250 keywords. But for the core question of "are my own pages getting found," scraping is now the expensive, shallow option.
GSC and Bing have the data for free, but raw. You get two dashboards, no SEO score, no per-page health, and a 50,000-row daily API cap per property to work around. You're left stitching it together yourself.
Sitemap-based tracking sits on the same free first-party data and does the stitching for you, page by page. That's the lane this guide lives in, and it's where tools like Quillly's rank tracking sit.
Run your Page Pulse check from your AI
If you already live in Claude, Cursor, or ChatGPT, you can run the whole check without opening a dashboard. With an MCP server connected, your AI reads the same rank data and reports back in plain language. Paste a prompt like this:
Pull my tracked pages for quillly.com. For each page, show
search position, 30-day clicks, index status, and SEO score.
Flag any page where one signal is out of line with the others:
- indexed but zero clicks
- ranking top 10 but low CTR
- high SEO score but not indexed
Then list the 3 pages worth fixing first and why.Your AI runs the read, sorts the mismatches, and hands you a short task list. No spreadsheet. You can run it Monday morning and have your week's SEO work scoped in one message.
Here's the weekly Page Pulse checklist to save:
[ ] Sitemap loads and
lastmoddates are current[ ] Every important URL shows as tracked
[ ] No page stuck on "Pending" index status for 7+ days
[ ] No top-10 page with a falling click trend
[ ] No high-SEO-score page pulling zero traffic
[ ] Pick the top 3 mismatches and fix one this week
The point isn't to stare at numbers. It's to turn a wall of position data into one decision: which page do I touch next? For more on closing that loop automatically, see our AI internal linking playbook.
Worked example: finding the fix in 142 pages
Here's how Page Pulse plays out on a real-sized site. Take a SaaS with 142 pages tracked: marketing pages, docs, and a blog. The 30-day view shows 3,480 search clicks, up 41%. Good headline. But the headline isn't where the work is.
Scan the four signals and three pages stand out:
/pricingranks #3 with 642 clicks. Healthy. Leave it./docs/quickstartshows "Pending" index status and ranks #18. It was updated last week and Google hasn't recrawled it. The fix is a re-notify, not a rewrite./integrationsranks #24 with 96 clicks and a falling trend. Position and traffic both sliding. This is content decay, and it needs a refresh.
Notice what the four signals did. The clicks number alone said "everything's up." The page-level view found a quickstart stuck in indexing limbo and an integrations page quietly decaying. Two concrete tasks, scoped in five minutes, that a keyword leaderboard would have buried.
That's the before-and-after. Before: one aggregate number trending up, and no idea what to touch. After: a re-notify on /docs/quickstart to clear the "Pending" state, and a refresh on /integrations to stop the slide. Same data Google and Bing already had about the site. The difference is reading it page by page instead of in aggregate.
When a page's rank drops: a 3-step triage
A page slips out of the top 10. Before you rewrite anything, run a fast triage. Most drops have a boring cause, and the four signals tell you which one.
Check index status first. If the page flipped to "Pending" or "Not indexed," it didn't lose a ranking battle. It fell out of the index. Re-notify Google and Bing, confirm the URL isn't blocked by robots or a stray noindex, and wait for a recrawl. This is the most common false alarm.
Compare clicks to impressions. If impressions held steady but clicks fell, your position is fine and the problem is the snippet. A weak title or meta description is letting the click go to someone else. Rewrite those before touching the body.
Look at the trend, not the day. A one-day dip is usually personalization or a SERP-feature shuffle, not a real loss. If the position has fallen for two weeks straight while a competitor climbs, that's genuine content decay, and the page needs a real refresh.
Work the steps in order. Indexing problems masquerade as ranking problems constantly, and you'll waste a rewrite fixing the wrong thing. The triage keeps you honest about which page actually needs work.
Frequently asked questions
Is rank tracking still worth it in 2026?
Yes, but the metric changed. Tracking individual keyword positions daily is mostly noise now, since AI Overviews and zero-click results mean position matters less than visibility and citation. Page-level tracking is worth it: knowing which of your URLs are indexed, ranking, and pulling traffic tells you where to spend effort. Track pages and trends, not single-keyword positions, and it stays valuable.
How often should you check keyword rankings?
Weekly is right for most sites. Positions swing hour to hour from location, device, and personalization, so daily checks mostly surface noise you'll react to and regret. A weekly Page Pulse check catches real trends, like a page slipping out of the top 10 or stuck on "Pending" indexing, without drowning you in fluctuation. Check daily only when launching a page or testing a specific change.
Can you track rankings without code?
Yes. Sitemap-based rank tracking needs no script, tag, or site change. You connect Google Search Console and Bing Webmaster Tools, which read search data those engines already collect, then point a tracker at your existing sitemap. It imports every URL and reports position, clicks, and indexing per page. Nothing gets installed on your site, and there's no migration involved.
Is Google Search Console enough for rank tracking?
GSC is the best free source of your own Google ranking data, but it's incomplete on its own. It covers only Google, samples query data, caps the API at 50,000 rows per property per day, and gives you no SEO score or per-page health view. Most people pair it with Bing and a layer that turns the raw rows into a page-by-page picture they can act on.
How do you track rankings on Bing and ChatGPT?
Connect Bing Webmaster Tools. Bing reports first-party position and click data the same way GSC does for Google, and it's the index behind ChatGPT search, so Bing visibility feeds AI answers. Use IndexNow to notify Bing the moment a page changes. Tracking Bing is the most direct proxy available for whether your pages can surface inside ChatGPT.
Did Google's num=100 change break rank tracking?
It broke cheap SERP scraping, not rank tracking itself. Removing num=100 in September 2025 forced third-party tools to paginate, pushing costs up roughly 8x and limiting many tools to the top 20–30 results. First-party tracking through Search Console and Bing was unaffected, because it never relied on scraping 100 results per query. That's a big reason page-level, first-party tracking is now the more reliable approach.
What's the difference between rank tracking and keyword tracking?
Keyword tracking starts from a list of search terms you choose and watches your position on each. Rank tracking, done page-first, starts from the URLs you own and watches how each performs across every query it ranks for. Keyword tracking misses long-tail queries you never added. Page-first tracking captures them automatically and maps directly to something you can edit.
The bottom line
Website rank tracking didn't die in 2025. The scraping-heavy, keyword-by-keyword version got expensive and shallow, while AI Overviews cut top-result CTR by 58%. The durable approach is first-party and page-first: read the search data Google and Bing already hold about you, one URL at a time.
Three things to take away. First, track pages, not keywords, because pages are stable and fixable. Second, watch four signals together with a Page Pulse check, since one number lies and four tell the truth. Third, you can do all of it without code, scrapers, or a migration, on a flat plan instead of a per-keyword bill.
Want to point this at the site you already run? Connect Quillly and track every page in 30 seconds.